
Simple, Efficient, and Robust Hash Tables for Join Processing
Simple, Efficient, and Robust Hash Tables for Join Processing
lvzhipin论文阅读:Simple, Efficient, and Robust Hash Tables for Join Processing
主要贡献:设计了一个新的哈希表:unchained in-memory hash table。
Abstract
哈希连接在关系数据处理过程起到了关键作用,并且他们的性能对于整个数据库的性能也起到了关键作用。由于中间结果难以预测,理想的哈希连接实现方式必须兼顾对典型查询快速和不寻常数据分布的鲁棒性。这篇论文中,我们实现了一个简单但高效的非链内存哈希表(unchained in-memory hash table design)设计。它组合了构建侧分区,邻接数组布局,流水线探测,布隆过滤器,以及软件写组合缓冲区等一系列技术,实现了在倾斜多对多连接时的性能提升,同时在处理一对多连接时仍能保持顶级性能。我们的哈希表的性能在关系查询中比开放寻址提升了2倍,在图处理查询中比开放寻址和拉链法提升了20倍。
Introduction
关系数据库依赖哈希连接有效处理join查询,而大多数查询的运行时间由join过程决定。底层哈希表有巨大的设计空间,有相当多的研究聚焦于分区、并行化以及倾斜处理。下面我们制定了一个高效哈希表的实现目标:
- 高效使用内存和缓存
- 高效执行CPU指令
- 高度可扩展的并行执行
- 对各种数据分布具有鲁棒性
这些标准经常相互冲突。比如通过调整哈希表的负载因子可以使用内存换取CPU周期。或者可以优化数据放置,其代价是复杂的锁定技术。这篇文章中设计了一个内存哈希表,在多对多以及经典的一对多连接。
哈希表没有最优的设计,所有设计都是在不同标准下的权衡。我们根据在许多基准测试和现实工作负载中发现的连接查询所做的观察来设计。下面是一些观察:
- 连接是不对称的,可能有小规模的build和大规模的probe端。
- 连接是选择性的,可能有许多probe在哈希表中没有发现匹配项
- 连接是可扩展的,因为输入可能很大,CPU内核是丰富的
- 连接可能有重复,因为元组可能有相同的key。
这些观察指导了我们的设计选择,我们的哈希表结合了构建侧分区、邻接数组布局,流水线探测,Bloom过滤器和软件写组合缓冲区技术,以实现高性能。
Design Criteria
Joins are asymmetric
许多连接是不对称的。哈希连接可以通过在小端build,在大端probe利用该不对称性。由于端的大小通常会相差几个数量级,因此probe阶段必须保持非常高效。沿着这些思路,我们可以在build端花费更多的CPU周期。下面的一些设计利用了这些不对称性(第三节会详细说明):
- 哈希表大小是2的幂,以增加内存消耗为代价使用单个移位指令计算索引
- 构建端被完全物化、分区和复制。而探测端避免了物化,并且将元组推入下面算子
- 元组存储在一个紧凑的邻接数组中,使得迭代匹配效率很高
Joins are selective
许多探测端元组可能没有匹配项。有效消除探测端中没有匹配项的元组是很重要的。布隆过滤器对于该任务是理想的:构建开销最小,高吞吐率,好的选择性。在3.2节,我们提出了优化的register-blocked Bloom filters以最小化查询次数,并且可以在没有空间开销的情况下嵌入哈希表。
另一个重要的方面是哈希函数。哈希连接必须权衡计算哈希值的成本和哈希值的良好分布。快速哈希函数容易造成倾斜,而通用哈希函数的计算通常非常昂贵。在3.2节,我们讨论了一个以crc32 CPU指令为基础的低计算开销并且分布良好的哈希函数。
Joins must be scalable
虽然哈希连接的构建端通常很小并且适合 CPU 缓存,但它仍然可以增长很大并且构建成本高。此外,最近的硬件趋势导致核心数量的增加;因此,并行化哈希表的构建对于利用现代硬件至关重要。大多数通用哈希表不支持高效的并行构建,因为它们 (1) 依赖于限制可扩展性的锁,以及 (2) 随着插入更多元组,调整哈希表的大小(该过程在并行环境下具有挑战性)。如第 3.3 节所述,可以通过多阶段构建过程来避免这些问题。
Joins can have duplicates
构建端具有相同键对于开放寻址法影响很明显,其中重复项按顺序存储,与哈希表的其他条目相冲突。而链接法的哈希表在这方面更加稳健,因为他们限制了重复条目对于目录中一个槽的影响。
链接允许使用嵌入式Bloom过滤器进行有效的探针,并且易于并行构建。然而,对于具有重复项的工作负载,长链会降低性能,因为它们无法有效地扫描,这降低了偏斜的鲁棒性。在第 3.1 节中,我们讨论了我们的unchained table,它允许对重复元组进行有效的迭代。
Approach
我们现在描述哈希表的设计。该设计遵循上一节中制定的目标,以允许高效探针、并行构建和对重复项的鲁棒性。3.1 Layout
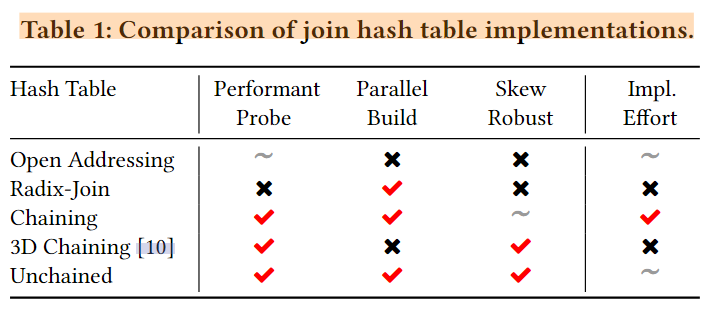
开放寻址法将所有元组存储在单个连续数组中,这对于使用非选择性谓词和无重复键进行探测是有效的。当连接具有选择性时,开放寻址方案不能有效地过滤掉不匹配的元组。当存在具有重复键的元组时,这些元组与其他键相冲突,从而导致高构建和探测成本。相比之下,链接哈希表构建一个与元组分开的目录。目录条目指向共享相同哈希前缀的元组,然后链接在链接列表中,减少由于重复而导致的冲突。但是,链接列表遍历是昂贵的,尤其是对于长链。为了解决这些问题,我们提出了unchained hash table layout,它结合了开放寻址和链接的好处。
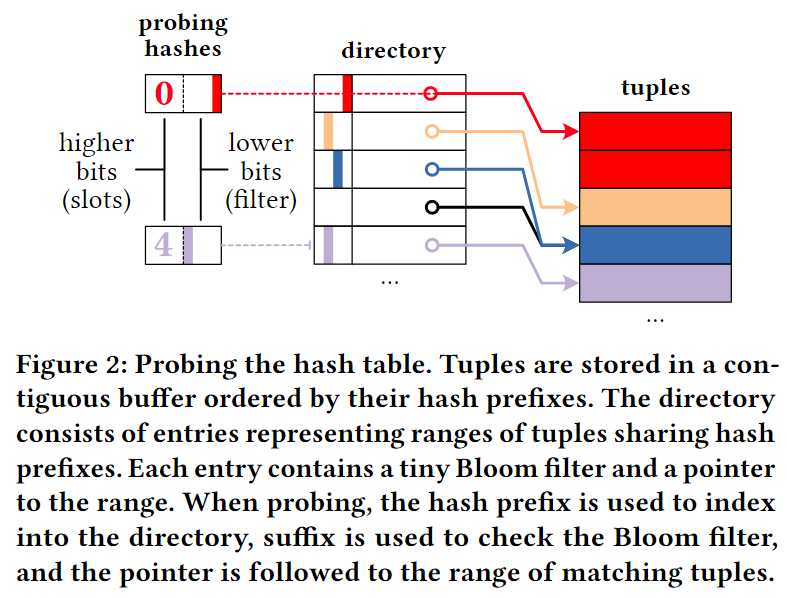
图 2 说明了我们的哈希表的基本布局,其中包含目录和元组存储。作为链接的替代方案,我们使用密集邻接数组进行碰撞解析:元组存储在由其散列前缀排序的连续缓冲区中。这样,元组以与目录中的指针相同的方式存储。邻接数组条目给出了拥有相同哈希前缀的元组范围,并且我们可以执行顺序扫描来访问这些元组。与链式哈希表相比,unchained消除了昂贵的指针跳转。与开放寻址方案不同,目录中的条目仅引用带有值的桶,并且重复项不会传播到相邻条目。我们测量了在我们的微基准测试中遍历链接列表的成本,相比于数组,如图3所示。遍历链接列表的成本比扫描邻接数组的成本增长得更快。
由于连接是选择性的,所以重要的是有效地和更早地消除没有连接伙伴的元组。我们在目录中的每个槽中嵌入寄存器阻塞的 Bloom 过滤器,以概率性地丢弃最终没有连接伙伴的元组。由于当前系统仅使用较低 248 个地址空间字节,因此指针的前 16 位未使用,我们可以使用这些存储过滤器。我们将指针存储在上位,将过滤器存储在下位。在访问元组存储之前检查Bloom过滤器,也可以推入其他操作符作为半连接约简器。
3.2 Efficient Probes
探测哈希表通常是连接执行中最昂贵的部分。探测端可以比构建端大几个数量级。因此,优化哈希表查找和最小化每元组工作是至关重要的。在下文中,我们描述了我们对unchained哈希表的高效探测。图 4 总结了探索哈希表中的元组的逻辑。我们优化了哈希函数、Bloom filter和哈希表的布局等几个方面来实现这一点。因此,过滤不匹配的元组只需要几个指令。


由于连接选择性,连接处理期间的热测试路径正在过滤掉找不到连接伙伴的元组。对于过滤,我们使用具有 16 位 的寄存器阻塞 Bloom 过滤器。为了实现低误报率,我们为槽中的每个元组设置了 4 位,这使我们能够丢弃未设置过滤器中任何相应位的探测元组。
我们的实现预先一次性计算所有可能的标签(16位中置4位)。在不成熟的实现中,计算这个标签需要几十个指令来计算位的位置(可能多个哈希函数)。为了在热路径中避免这些,我们改为使用预先计算的查找表,该查找表存储$ 16 \choose 4 $ = 1820 个不同的位模式并将它们加载到单个指令中。请注意,我们将此查找表使用均匀采样填充为 2^11 = 2048 个条目,以便能够使用单个移位指令计算索引。为了测试所有都设置在 Bloom 过滤器中,我们对过滤器进行按位取反,并与标签进行按位与。这也可以充当空指针检查并转换为高效指令,即在 x86 上转化为单个 ANDN。因此,过滤元组的热路径仅包含五个指令和一个分支。图 6 显示了检查的逻辑。
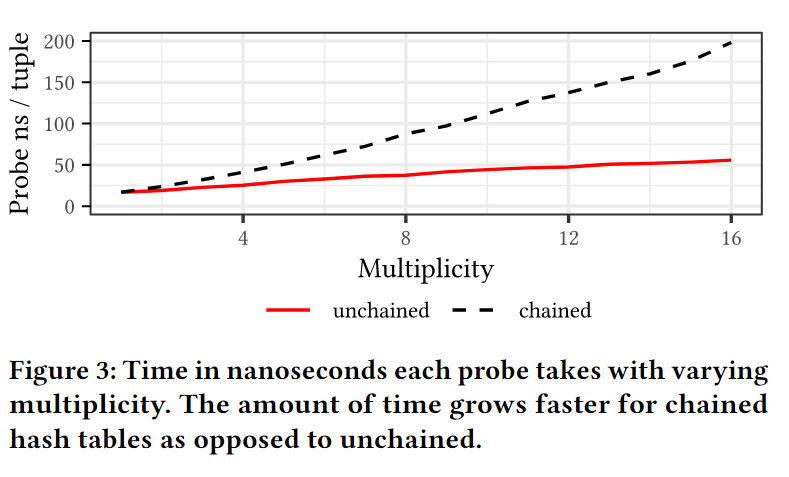
与动态计算标签相比,使用预先计算的查找表有几个理想的优势:预计算标签只需要4KB内存,最多消耗1个TLB条目。因此,加载标签几乎与动态计算单个位标签一样便宜。此外,4 位标签误报率更低。对于单个哈希,误报率为 1/1820,而不是具有单个位标签的 1/16。我们在图 5 中分别使用和不使用过滤器评估了探针性能。我们发现,对于非选择性连接,Bloom 过滤器的开销很低,对于选择性连接则非常有效。
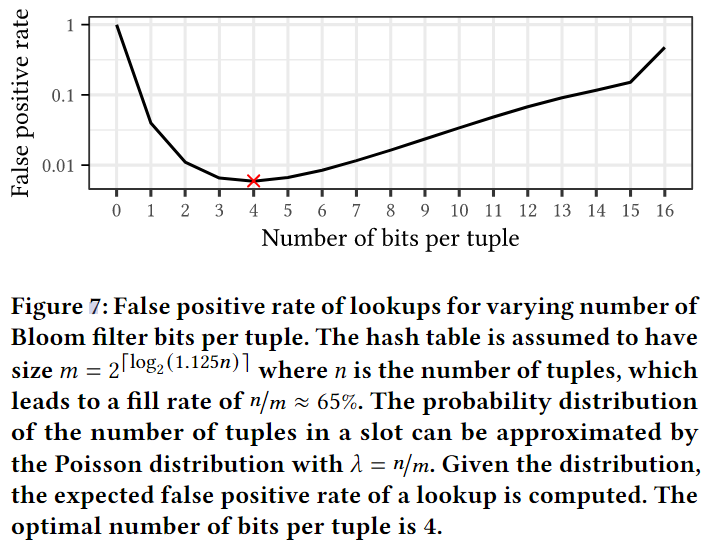
每个标签的位数影响误报率。如果使用的位过少,则标签的数量就很少,从而导致不同哈希值分配给相同的标签。如果使用过多的位,不同标签之间的相互影响会更严重。这两种情况都会增加假阳性率。因此,给定哈希表的负载因子,我们可以确定标签的最佳位数。图7显示了不同位数的误报率。我们的哈希表负载因子为65%,每个元组4比特,1820个标签是最优的,假阳性率为1/169。带有2048个标签的填充查找表的假阳性率略高,为1/168。

3.3 Parallel Build
对于链式哈希表,Leis 等人描述了一种并行高效构建哈希目录的方法。然而,我们提出的在邻接数组中重复存储的方法需要更多的同步,我们通过分区来实现这一点。在构建哈希表的第一步,我们收集连接build端的所有元组,并对其进行哈希分区。与 Richter 等人的做法类似,我们使用slap allocator来存储初始元组,从而保持它们在内存中的密度。不过,对于用作最终元组存储的邻接数组,我们使用的是连续的内存块。在最终存储中,元组根据哈希值排序;与目录中的单个条目相对应的所有元组都存储在一个连续的内存块中,目录中的相邻条目按哈希值顺序指向相邻的元组块。为了确定元组在最终存储中的分布情况,我们会计算每个目录条目的元组数量。然后,将元组写入最终存储器,同时更新目录。
3.3.1 Tuple Collection
在数据库查询的执行计划中,哈希连接可能位于许多操作符之上,这些操作符产生的数据被输入到join中。这些数据以元组流的形式从不同线程中产生。元组的总量事先并不知晓,对其的估计也可能不准确。Tuple Collection必须处理这种不确定性,并能处理并发产生的不同数量的元组,将其物化,并在构建目录前对其进行哈希分区。
由于需要同时分配和物化许多元组,因此tuple collection通常会受到内存分配器的瓶颈制约。为了避免这一瓶颈,我们使用了slab allocator,它以大块的形式分配内存,然后将这些大块的内存分配给单个元组。这减少了系统调用的次数和全局内存分配器内的竞争。在构建完成后一次性释放内存。
元组的分区使bump allocation策略变得复杂,因为我们希望同一分区内的元组在内存中大部分是连续的,以便对单个分区内的元组进行高效迭代。为此,我们使用了三级bump allocator。第一层为每个线程以块为单位分配内存,第二层为每个分区分配较小的块,第三层从小块中分配单个元组。其伪代码如图 9 所示。

如果分区数量过多,tuple collection可能会产生昂贵的 TLB misses。我们的多级分配方案避免了这一问题,因为小块通常共享同一个内存页,而在 2 MB 或 1 GB 大内存页的情况下,共享的可能性更大。这与软件写合并缓冲区的效果类似,但不增加成本。
收集完所元组后,需要在线程间交换分区。这需要利用bump allocator的内部结构来完成。bump allocator将内存块存储在一个链表中。线程在处理分区之前,会合并所有线程中与该分区相对应的内存块链表。之后,就能以单个分块列表的形式对元组进行高效迭代。
3.3.2 Tuple Counting
元组收集完成后,我们需要构建目录,并将元组最终复制到的紧凑元组存储区。要将元组复制到最终位置,我们首先需要确定共享相同哈希前缀的元组的存储范围。这需要计算每个目录条目的元组数量。然后使用 排他性前缀和 对目录的计数进行处理,以确定元组的存储范围。然后使用这些范围将元组复制到最终存储中的相应位置。
3.3.3 Copies
构建过程的最后一步是将元组复制到元组存储的最终位置。计数后,每个目录条目都包含共享相同哈希前缀的元组范围的起点。当我们遍历元组时,我们会将元组复制到起始位置,然后递增起始指针。最后,每个目录条目都将指向相应范围的终点,因此可以使用前一个条目的指针来确定起点。此外,一个特殊的目录项 directory[-1]用于指向元组存储空间的最开始。具体做法是,首先为表分配一个额外的空间,将第一个条目设置为元组存储空间的起点,然后将指向目录的指针向前移动一个条目。使用特殊条目可以避免探测时可能出现的分支。计数和复制的伪代码如图 10 所示。

3.4 Handling Large Tuple Sizes
只要元组足够小,可以放入高速缓存行,复制元组的成本就相对较低。请注意,只需两条加载指令和存储指令,就能复制所有大小不超过 CPU 向量宽度两倍的元组。要做到这一点,可以使用不大于元组大小的最大矢量宽度,然后在元组的起点和终点各使用一条加载/存储指令。例如,如果我们的元组是 24 字节,而 CPU 的矢量宽度是 16 字节,那么我们的第一个加载/存储对复制的是 0-15 字节,第二个加载/存储对复制的是 8-23 字节。
如果元组非常大,我们需要另一种方法来提高构建效率。在这种情况下,我们会将元组链入一个链表,而不是将它们复制到连续的存储空间。这在一定程度上提高了构建过程的效率,因为我们不需要复制元组。不过,我们必须更新元组中的链表指针,由于内存写入放大,包含指针的整个缓存行都会被写回内存。不过,对于大于一个高速缓存行的元组来说,链接还是值得的。
将元组链接到目录条目是一个相对简单的操作,如图 11 所示。目录条目指向上一个链接的元组,而元组又指向上一个元组,这样就建立了一个链接列表。只需一个 xchg(原子交换) 就能更新该条目指针,只需一个 or 就能更新标签。这些操作可以通过原子对应操作实现线程安全。由于原子变体的简单性,可以避免初始分区阶段,从而增加了目录构建过程中的竞争,但降低了初始收集的成本。

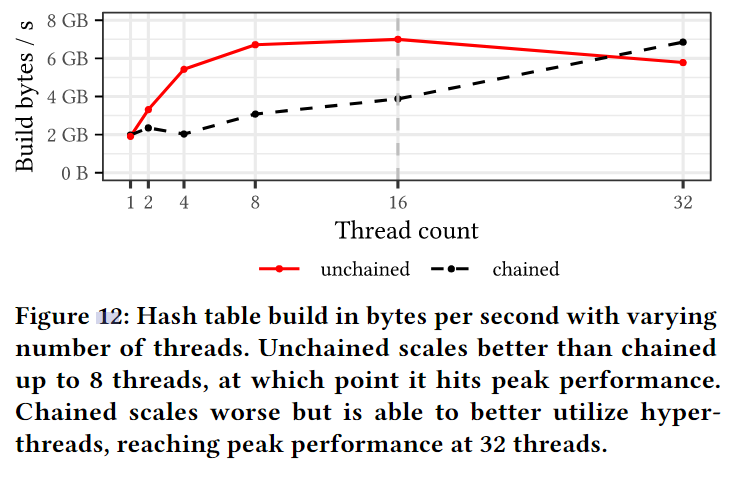
在图 12 中,我们比较了在不同线程数下使用非链式哈希表与使用原子和无分区构建的链式哈希表所需的时间。我们发现,非链式构建几乎只需 8 个线程就能达到峰值性能,而链式构建则需要全部 32 个超线程才能达到相同的性能水平。
3.5 Large Memory Allocation
在第 3.3.1 节中,我们讨论了元组收集的内存分配策略。下面,我们将讨论散列表本身的内存分配问题。由于哈希表是一个大的连续内存块,其内存管理基本上由一对 malloc 和 free 调用组成。不过,由于分配的块可能很大,因此会出现许多微妙的问题。
在 Linux 中,mmap 系统调用用于向操作系统请求连续的虚拟内存块。调用 mmapcall 后,虚拟内存尚未得到任何物理内存的支持。当内存被访问时,操作系统会按需懒散地分配物理内存页,并用零填充。不过,如果对页面的首次访问是读取,操作系统会将虚拟页面映射为只读的 0 页面。随后的任何写入操作都会触发新物理页面的分配,虚拟页面也会重新映射到新页面。由于与零页的原始映射可能缓存在不同 CPU 内核的 TLB 中,因此操作系统必须进行 TLB 销毁。TLB 崩溃的成本非常高,因为它需要操作系统发送处理器间中断。为了避免代价高昂的 TLB 崩溃,对最近分配的页面进行的所有初始操作都应该是写操作。例如,链式哈希表在链接目录条目中的元组时,应优先使用 xchg 指令,而不是 load/cmpxch 对。
当释放内存时,也会出现类似的问题,因为 munmap 同样需要 TLB 销毁。因此,稍后异步执行 munmap 操作有利于避免降低关键查询的速度。由于 Umbra 是作为服务器数据库系统设计的,因此它可以通过单个 mmap 调用预先保留整个内存,然后在内部进行管理,从而避免这些问题。在数据库关闭之前,不会将内存交还给操作系统。
Evaluation
我们在微基准测试和关系数据库 Umbra 中实现了unchained table。我们在一台拥有 16 个内核、32 个线程和 64 GB 内存的 AMD Ryzen Zen3 5950X 机器上运行了基准测试。图 3、图 5 和图 12 中的微基准测试使用的是哈希表,每个哈希表有 720720 个大小为 32 字节的元组。此外,我们还在关系基准 TPC-H SF {1, 10}、TPC-DS SF {1, 10} 和 JOB [18 ];图基准 LDBC SNB BI [27 ] SF 10 和 CE [7] (仅产生少于 109 个结果元组的查询)上使用所有硬件线程对 Umbra 进行了评估。所有查询均重复 10 次,我们报告的是运行时间的中位数。
我们根据经验评估了哈希表的负载系数以及 couldContain 的相应误报率(参见图 4)。在输入大小均匀分布的情况下,我们的哈希表的负载率约为 0.65,考虑到链长度的分布,误报率为 1/168。
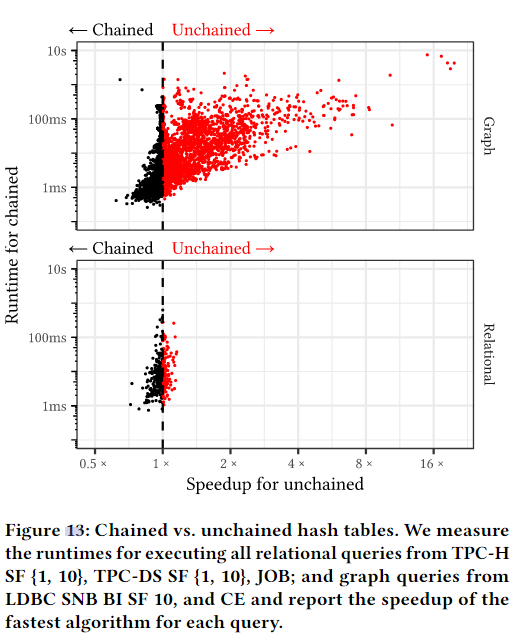
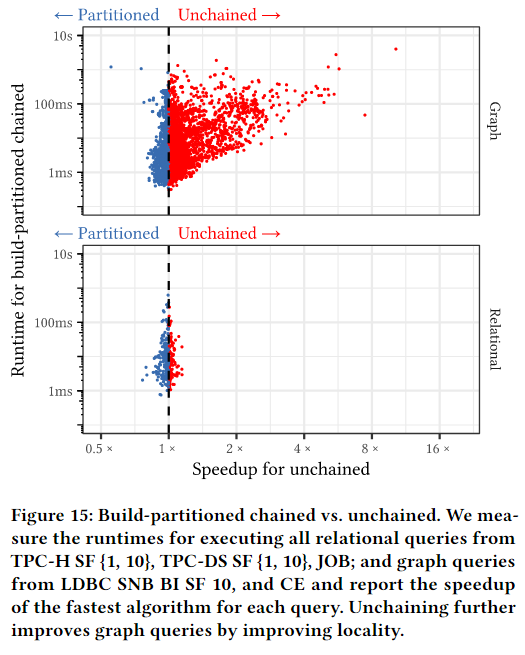
为了衡量非链式(使用构建分区)和链式(不使用分区,如 Hyper 和 DuckDB )哈希表的相对性能,我们执行了上述基准测试中的所有 10312 个查询,并在图 13 中报告了每个查询的非链式速度提升情况。对于绝大多数查询,两个哈希表的性能相似,没有明显的加速或减速。不过,对于微小的查询,链式散列表的运行时间最多可缩短 30%,因为表足够小,可以放入缓存中进行探测,分区的构建开销(需要复制)也就显而易见了。相比之下,对于大型查询,非链式哈希表设计是有益的,因为它避免了建表的原子指令,并改善了探测的内存访问模式。特别是在图形工作负载中,对于运行时间超过 100 毫秒的昂贵查询,非链式设计最多可将性能提高 20 倍。对于这些查询,哈希表包含更多具有重复键的元组,链式设计导致每个元组都要进行一次随机内存访问,因此成本很高。解链技术通过在内存中连续存储元组解决了这一问题。
图 13 左上角的两个图形查询(dblp_cyclic_q9_06 和 hetio_cyclic_q9_12)是具有巨大构建侧的查询,其中单个分区无法放入 L1 缓存。当单个分区无法放入低级缓存时,就会大大降低元组的复制速度。yago_acyclic_Star_6_{42, 43},即图 13 左下角的两个图查询,是分区数过高导致构建侧很小的查询。根本问题在于,我们的实现在构建之初就设置了一次分区计数。这个初始分区计数基于启发式方法,如基数估计和线程数。这些启发式方法并不完美,可能会导致次优的分区计数。未来,我们计划探索自适应分区方案,从较低的分区计数开始,随着收集的元组增多而增加分区计数。
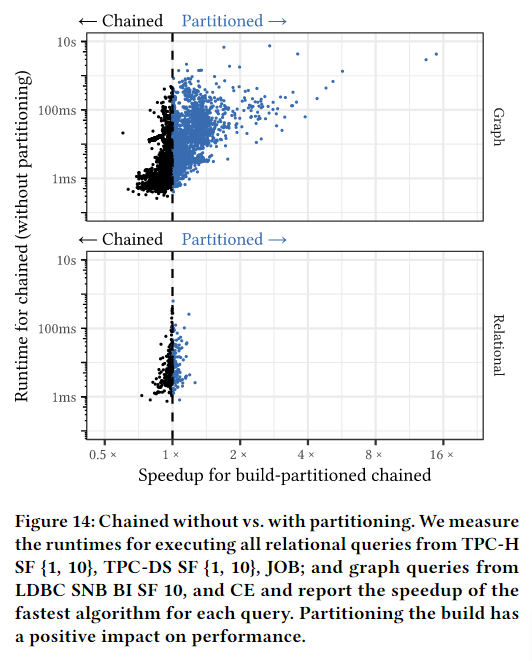
为了更好地展示分区收集和随后复制元组的单独影响,我们在 Umbra 中实施了构建分区链。我们在图 14 中比较了有分区和无分区链式处理的性能。我们可以看到,分区通常会提高同一链中的元组在内存中更靠近的可能性,从而改善局部性。不过,通过将元组复制到连续存储区来解链的效果更好。我们在图 15 中比较了未链化和链化与构建分区的性能。我们发现,unchained可将图查询的性能最多提高 10 倍。
接下来,我们将测量哈希表在大型工作负载上的性能,并将其与最先进的数据库系统进行比较。我们使用 TPC-H SF 100 和 1000,它们运行在一台较大的机器上,该机器配备了两个 AMD EPYC 7713 CPU(128 个内核、256 个线程和 256 GB 内存)。作为竞争对手,我们选择了 Hyper v0.0.18825 [ 13 ] 和 DuckDB v0.10.1 [ 23 ] 这两个高性能分析查询引擎。Hyper 和 Umbra 使用查询编译,DuckDB 使用矢量化[ 5 ]。所有系统都采用 morsel-driven 并行[17]。
图 16 显示了三种哈希表设计在 TPC-H 基准测试和两个竞争对手测试中的性能。我们发现,我们的链式和非链式哈希表性能最佳,比 Robin Hood 开放寻址哈希表平均快 2 倍。与开放寻址相比,我们的高效探测和构造使这两种设计具有显著优势。与其他系统相比,Umbra 比 Hyper 快 2 倍,比规模因子为 100 的 DuckDB 快 6 倍。同样,我们的设计可以很好地扩展到更大的工作负载,而且我们可以高效地并行构建表。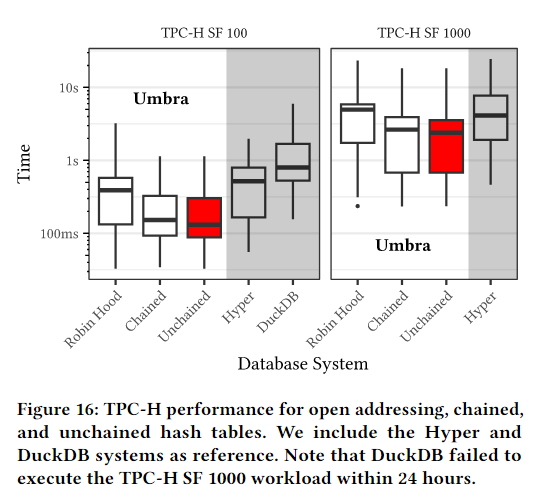
总结:
文章要解决的问题(背景)
提升哈希连接的性能
文章的贡献
设计了一种新的非链式哈希表,主要的特性如下一一列举。
非链式
优点
非链式相比于开放寻址法,可以有效降低重复键带来的冲突影响(非链式采用bucket,重复键带来的影响会被限制在同一个bucket内),以及可以有效过滤(当连接具有强烈的选择性时,可以在bucket中嵌入一个布隆过滤器,进行简单过滤)。
非链式相比于链式哈希表,在顺序扫描某个bucket时,消除了昂贵的指针跳转。
文章中说,非链式结合了两种方式的优势
缺点
非链式相比于链式,虽然可以规避probe时的指针跳转,但是也增加了build时的复制开销。这对于tuple很大时非常不友好,不过文章中提到了此时可以使用链表。
同时,非链式额外添加的布隆过滤器会带来新的开销。如果选择性比较弱,布隆过滤器可能作用很小。
布隆过滤器
特点
布隆过滤器放置在不会被使用的高16位地址中,这降低了其内存开销。
每个元组有4位的tag(16位中置4位,这是实验验证的对应负载因子下的最优位数)。
预先一次性计算所有可能的标签,共$ 16 \choose 4 $ = 1820 种,将其均匀采样填充为 2 ^ 11 = 2048个条目。预先计算并加载到内存中,这样在计算tag和判断tag是否在过滤器中时就少了计算步骤,而是直接从数组中取出即可,降低了计算开销。
哈希函数
简单哈希函数分布比较差,复杂哈希函数计算成本高。使用CRC指令写了一个对32位输入和64位输入的专用哈希函数。
分区构建
并行构建哈希表时,使用分区收集进行收集。对于每个线程来说,对其收集到的数据进行分区,然后放到分区块中(第一次复制)。然后所有线程收集完成后,在处理分区前,会合并所有线程中与该分区相对应的内存块链表。之后,以分块列表的形式可以对元组进行高效迭代(统计directory中的元组数量以及复制到最终位置)。
分区的意义在于有利于统计和第二次复制时迭代高效。
至于为什么不只用一次复制并行构建哈希表,可能是因为需要先收集所有元组进行count(统计每个directory中的元组数量),才能进行最终位置的复制。
评估
非链式相对于链式,只在大型查询(图查询)时性能更好,对于微小的查询甚至链式会更优。
对于有分区和无分区元组收集的链式,有分区仍然可将图查询性能提高。
总体来说,无论是链式还是非链式,作者设计的哈希表都比DuckDB和Hyper性能好很多。但是性能好的原因到底是什么?不一定是文章中描述的非链式带来的优势(非链式只比链式好了一点)。可能是其他设计带来的优势(Umbra?可能需要看一下这篇文章)?
总结
这篇文章描述了很多想法和技术,有些很有想象力。unchained比chained优势在于复杂查询(图查询)的性能提升巨大。
